
14. Random Forest
18 Jan 2022- 1. Giới thiệu
- 2. Voting
- 3. Phương pháp lấy mẫu
- 4. Random Forest
- 5. Đánh giá và kết luận
- 6. Tham khảo
1. Giới thiệu
Ở bài 12 và bài 13 mình đã giới thiệu về mô hình Decision Tree sử dụng các độ đo khác nhau để tìm ra được cây quyết định, ngoài ra lớp mô hình này có thể làm việc với cả 2 bài toán Classification và Regression. Ý tưởng chính của nó là xây dựng một chuỗi câu hỏi từ trên xuống để đưa ra dự đoán ở leaf node kết thúc. Mặc dù tính mạnh mẽ của nó đã được thể hiện nhưng những hạn chế còn lại khá nhiều, có thể kể đến là: dễ xảy ra hiện tượng Overfiting, không quá tốt trong các bộ dữ liệu lớn… và một điểm yếu khác đó là mô hình chỉ đưa ra dự báo dựa trên một kịch bản duy nhất (một cây được tạo ra), điều này sẽ làm cho sự phụ thuộc vào các thuộc tính được lựa chọn ở trên đỉnh rất cao, cho nên khi điểm một dữ liệu ‘lạ’ sẽ không được dự đoán chính xác nếu mô hình không đủ tốt.
Giả sử sau một năm làm việc mệt nhọc, bạn muốn tìm một nơi du lịch phù hợp với túi tiền mà vẫn mang lại cảm giác thoải mái. Để tìm được một địa điểm phù hợp, bạn có thể tìm kiếm thông tin trên mạng, đọc các reviews từ các travel blog hoặc hỏi những người bạn xung quanh… Giả sử rằng bạn đã tìm ra được một list các địa điểm phù hợp nhưng đang phân vân chưa biết chọn ra một nơi phù hợp nhất. Tiếp tục bạn sẽ gửi list này cho những người bạn và yêu cầu họ chọn ra địa điểm mà họ cho là tốt nhất. Và cuối cùng địa điểm mà bạn chọn lựa là địa điểm có lượt chọn cao nhất.
Ở ví dụ trên để có được kết quả cuối cùng ta có thể chia làm 2 bước:
-
Bước 1: Hỏi ý kiến cá nhân mỗi người về địa điểm mà họ cho rằng là tốt. Việc này giống với thuật toán Decision Tree.
-
Bước 2: Tổng hợp ý kiến của mọi người và chọn lựa nơi được chọn nhiều nhất. Và thực tế cho thấy rằng câu trả lời mà được mọi người trả lời nhiều nhất thường đạt được kết quả tốt. Thật vậy, việc tổng hợp từ nhiều nguồn thường sẽ đưa ra một kết quả tốt hơn cá nhân (hiệu ứng đám đông - wisdom of the crowd).
Trong Machine Learning có một kĩ thuật tương tự đó là Ensemble Learning. Kĩ thuật này còn có thể sử dụng để cải thiện độ yếu kém của một cây quyết định duy nhất. Các nhà nghiên cứu đã đề xuất một phương pháp cải tiến đó là hợp nhất nhiều cây quyết định hơn để đưa ra kết quả. Và ý tưởng của sự kết hợp nhiều cây này sẽ tạo thành thuật toán Random Forest (rừng ngẫu nhiên). Thuật toán này có thể làm việc với 2 mô hình: classification và regression.
2. Voting
Để hiểu rõ phương pháp tổng hợp rồi đưa ra kết quả, mình sẽ giới thiệu tới một số ví dụ và thực nghiệm sau. Giả sử bạn có training một số mô hình classification như: Logistic Regression, SVM, Decision Tree, KNN… và đạt được kết quả khoảng 80% accuracy cho mỗi mô hình. Tuy nhiên, bạn đã thử thay đổi các tham số trong mô hình nhưng độ hiệu quả không có nhiều khác biệt. Vậy liệu có cách nào để cải thiện hơn? Một cách đơn giản đó là sử dụng kĩ thuật Ensemble Learning, tức vẫn training mỗi mô hình riêng biệt nhưng ở kết quả cuối cùng ta sẽ tổng hợp và voting ra nhãn được xuất hiện nhiều nhất làm kết quả cuối cùng.
Fact: trong các cuộc thi về học máy trên Kaggle, các bài đạt top đều sử dụng ý tưởng từ Ensemble Learning.
Để chứng minh cho sự hiệu quả những gì mình đã đề cập bên trên, mình sẽ sử dụng phương pháp Ensemble Learning dùng cho bài toán phân loại ung thư và so sánh với các mô hình duy nhất:
- Import thư viện cần thiết và normalize dữ liệu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# Load the dataset
iris = load_breast_cancer()
X = iris.data
y = iris.target
# Normalize
scaler = MinMaxScaler()
scaler.fit(X)
X = scaler.fit_transform(X)
# Split dataset
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.25,random_state=42)
- Tiếp theo mình sẽ khởi tạo 3 mô hình:
LogisticRegression, SVM, DecisionTreevà một mô hình tổng hợp của 3 mô hình trênVotingClassifiervới trọng số voting của 3 mô hình là tương đương nhau (voting = hard):
1
2
3
4
5
6
7
8
9
10
# Different models
log_clf = LogisticRegression()
svm_clf = SVC()
tree_clf = DecisionTreeClassifier()
# Ensemble learning of different models
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('svc', svm_clf), ('tree_clf', tree_clf)],
voting='hard'
)
- Bắt đầu training mô hình và xem kết quả đạt được:
1
2
3
4
for clf in (log_clf, svm_clf, tree_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
- Kết quả:
1
2
3
4
LogisticRegression 0.986013986013986
SVC 0.9790209790209791
DecisionTreeClassifier 0.958041958041958
VotingClassifier 0.986013986013986
Như đã thấy thì kết quả của mô hình VotingClassifier đạt được kết quả cao nhất là 0.986 so với các mô hình đơn lẻ, trong khi đó mô hình thấp nhất là DecisionTreeClassifier 0.958 (cách biệt gần 0.28). Đây là một cải thiện khá tốt. Mô hình có thể tưởng tượng như sau:
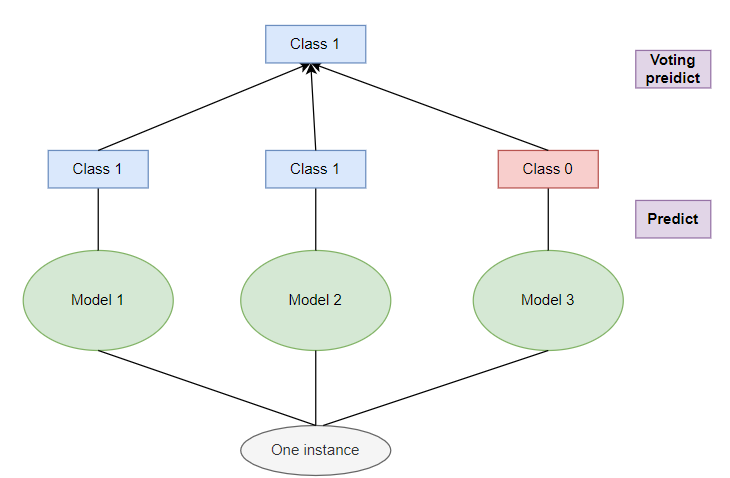
Ngoài ra nếu bạn muốn lấy ra xác suất của từng nhãn thì cần thay thế hàm predict bằng predict_proba và thay đổi phương thứ voting từ hard sang soft ở class VotingClassifier. Xác suất dự đoán ở mỗi class sẽ là giá trị trung bình của từng model. Tuy nhiên, để làm cho mô hình Ensemble Learning đạt được hiệu quả thì các thuật toán bên trong cần phải khác nhau tức các mô hình bên trong hoàn toàn độc lập và không liên quan gì tới nhau và mang tính khách quan cao hơn. Vậy với mô hình Random Forest thì sao trong khi các thuật toán như mình đã đề cập bên đều sử dụng mô hình Decision Tree? Ở phần tiếp theo, mình sẽ tiếp tục giải thích cụ thể ở phần dưới.
3. Phương pháp lấy mẫu
Như đã đề cập bên trên thì để một mô hình Ensemble Learning hiệu quả thì ta có thể sử dụng nhiều mô hình khác nhau trên cùng một tập dữ liệu. Tuy nhiên còn có một cách khác rất hiệu quả mà chỉ sử dụng một mô hình đó là training trên các tập con ngẫu nhiên của tập dữ liệu mẫu. Và có 2 cách để thực hiện việc lấy ra tập dữ liệu con hiệu quả đó là: Bagging và Pasting.
3.1. Bagging và Pasting
Bagging hay còn có thể gọi là Boostraping, là phương pháp lấy mẫu có trùng lặp. Giả sử ta có tập dữ liệu ban đầu là $\mathcal{D} = {(x_1, y_1), (x_2, y_2), \dots, (x_m, y_m)}$ bao gồm $m$ điểm dữ liệu và $n$ features. Gọi tập hợp gồm các tập dữ liệu con ngẫu nhiên được lấy từ tập dữ liệu ban đầu có tên là $\mathcal{B}$. Với mỗi tập con trong $\mathcal{B}$ sẽ lấy mẫu bằng cách khi mình sampling được 1 dữ liệu thì mình không bỏ dữ liệu đấy ra mà vẫn giữ lại trong tập $\mathcal{D}$, rồi tiếp tục sampling cho tới khi sampling đủ $m$ dữ liệu hoặc đủ số lượng mình yêu cầu. Ví dụ minh họa:
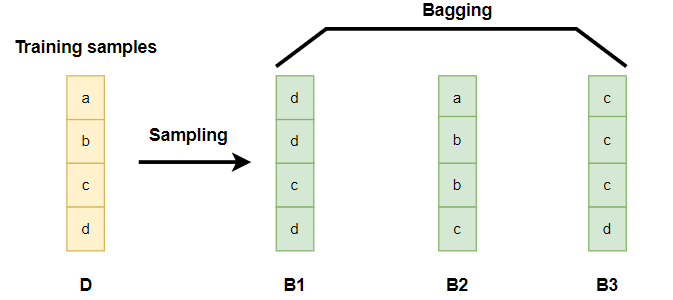
Pasting cũng tương tự như Bagging nhưng khi lấy mẫu sẽ không lấy những dữ liệu trùng lặp.
Và lúc này sau khi ta đã thu được 3 tập dữ liệu $B_1, B_2, B_3$ như hình trên ta sẽ tiến hành training một mô hình trên mỗi tập dữ liệu. Cuối cùng kết quả đánh giá sẽ là giá trị có tần suất xuất hiện nhiều nhất (voting) cho bài toán classification, hay giá trị trung bình cho bài toán regression. Tổng quan hóa qua hình minh họa sau:
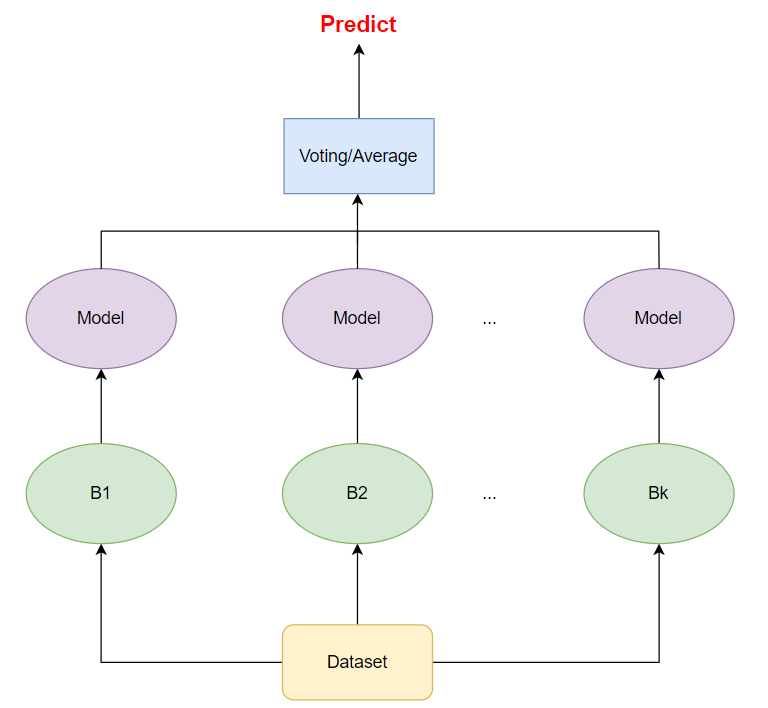
Như bạn đã thấy thì sẽ có nhiều mô hình với các tập dữ liệu khác nhau (lấy từ dữ liệu gốc). Vì mỗi mô hình là không hề liên quan tới nhau nên chúng ta hoàn toàn có thể train các mô hình này song song. Vì có thể tính toán song song nên các phương pháp bagging và pasting được sử dụng rất rộng rãi.
3.2. Thực nghiệm với Python
Để thực nghiệm với các giải thích mà mình đã đề cập bên trên cũng như còn có một số lưu ý nên mình sẽ thực hiện training trên bộ dữ liệu ung thư ở phần trên. Trong sklearn đã cung cấp class BaggingClassifier cho bài toán phân loại và BaggingRegressor cho bài toán hồi quy nên mình sẽ sử dụng luôn.
Cụ thể mình sẽ training trên 500 mô hình DecisionTree (n_estimators) với 100 samples (max_samples) ngẫu nhiên được lấy từ training set với phương pháp Bagging (bootstrap=True), nếu lấy theo phương pháp Pasting (bootstrap=False).
1
2
3
4
5
6
7
8
9
from sklearn.ensemble import BaggingClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(),
n_estimators = 500,
bootstrap=True,
max_samples = 100,
)
bag_clf.fit(X_train,y_train)
y_pred = bag_clf.predict(X_test)
Kết quả đã được cải thiện so với mô hình Decision Tree được training duy nhất trên toàn bộ dữ liệu:
1
2
print(accuracy_score(y_test, y_pred))
>>> 0.965034965034965
Như đã thấy thì các tập dữ liệu sử dụng boostraping sẽ rất đa dạng, điều này có thể làm cho mô hình có chút (high bias) underfitting so với pasting (dữ liệu ít đa dạng hơn). Tuy nhiên khi kết hợp thì các mô hình sẽ càng ít liên quan tới nhau nên sẽ giảm (low variance) overfitting hơn. Và thông thường thì boostraping đưa ra những kết quả tốt hơn nhưng nếu có thể thì nên sử dụng cả 2 phương pháp rồi so sánh.
Ngoài cách lấy mẫu dựa trên phương pháp tạo ra nhiều phiên bản khác nhau của các instances trong dữ liệu ban đầu thì ta còn có một cách khác đó là tạo ra các phiên bản khác nhau của dữ liệu dựa trên các features. Phương pháp này khá thú vị và tạo ra các kiểu dữ liệu rất đa dạng, và nó sẽ có thể ứng dụng vào các tập dữ liệu cao chiều. Về cách hoạt động thì hoàn toàn tương tự boostraping và pasting. Bạn có thể đọc thêm tại đây.
4. Random Forest
4.1. Ý tưởng chính
Sau tất cả các phần mình đã giới thiệu và giải thích bên trên thì thuật toán Random Forest sẽ rất đơn giản để hiểu. Thuật toán này sẽ áp dụng cả 2 phương pháp Ensemble Learning và Boostraping. Ở phần Boostraping, thuật toán sẽ dựa trên dữ liệu ban đầu mà tạo một tập hợp gồm các tập dữ liệu con. Ở phần Ensemble Learning sẽ là tổng hợp nhiều mô hình Decision Tree dựa trên mỗi tập dữ liệu con.
Tuy nhiên có một chút khác biệt là: (i)tập dữ liệu con này yêu cầu phải có cùng số lượng instances với dữ liệu gốc; (ii)cách phân tách ở mỗi node sẽ không dựa trên thuộc tính phân chia nhãn tốt nhất mà chọn ngẫu nhiên một tập hợp con của các thuộc tính và nó tìm kiếm thử nghiệm tốt nhất có thể liên quan đến một trong những thuộc tính này.
Để hiểu rõ hơn thuật toán thì bạn có thể hiểu đơn giản các bước sẽ được tổng quát như sau:
Bước 1: Cho một tập dữ liệu $D$ có $m$ điểm dữ liệu (instances) và $n$ thuộc tính.
Bước 2: Giả sử ta có $T$ cây quyết định, tức ta cũng cần có $T$ tập dữ liệu được boostraping từ dữ liệu ban đầu và mỗi tập dữ liệu này phải có $m$ instances và $d$ thuộc tính. Tại cây thứ $i$:
-
Tại mỗi node:
-
Chọn ngẫu nhiên $k$ thuộc tính ($k < d$).
-
Từ các thuộc tính $k$ được chọn chia ra các nhánh con tương ứng.
-
-
Cây được phát tiển tới khi đạt được ngưỡng lớn nhất có thể (không dừng, không pruning).
Bước 3: Giá trị dự đoán cuối cùng có thể là voting cho bài toán phân loại hoặc lấy trung bình cho bài toán hồi quy.
Như đã thấy thì việc xây dựng mỗi cây quyết định trong Random Forest mang tính ngẫu nhiên rất cao và phát triển hết mức có thể nên kết quả cuối cùng của mỗi cây sẽ khá khác nhau và sẽ bị Overfitting. Tuy nhiên, việc kết hợp những cây yếu này làm cho chúng có thể bù trừ cho nhau những điểm mạnh, yêu của mỗi cây và tạo ra một mô hình tốt (Random Forest).
4.2. Thực nghiệm với Python
Trong sklearn đã cung cấp class RandomForestClassifier cho bài toán phân loại và RandomForestRegressor cho bài toán hồi quy. Có một số hyper-parameters cần lưu ý khi khởi tạo mô hình: số lượng cây (n_estimators), số lượng tối đa thuộc tính được lựa ở bước 2 (max_featuers) và một số thuộc tính tương tự ở bài Decision Tree và Bagging bên trên.
Với tập dữ liệu phân loại ung thư bên trên, mình sẽ khởi tạo mô hình RandomForestClassifier bao gồm: 500 cây, mỗi cây có độ sâu tối đa là 20, số lượng leaf node tối đa là 20.
1
2
3
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500,max_depth= 20, max_leaf_nodes=20)
rnd_clf.fit(X_train, y_train)
Kết quả:
1
2
3
y_pred = rnd_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
>>> 0.972027972027972
Và tất nhiên ta có thể sử dụng class BaggingClassifier để tạo mô hình tương tự như RandomForestClassifier bên trên:
1
2
3
4
5
6
7
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_depth= 20, max_leaf_nodes=20,),
n_estimators=500, max_samples=1.0, bootstrap=True)
bag_clf.fit(X_train,y_train)
y_pred_rf = bag_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_rf))
>>> 0.972027972027972
Ngoài ra nếu cần tăng tính ngẫu nhiên khi chọn thuộc tính ở mỗi node bạn có thể tham khảo thêm và phần ExtraTreesClassifier.
Toàn bộ source code của bài được lưu tại đây.
5. Đánh giá và kết luận
-
Random Forest là thuật toán có những cải tiến cực tốt từ việc tổng hợp các Decision Tree, việc giảm Overfitting và có thể làm việc tốt cho các tập dữ liệu cao chiều làm cho Random Forest trở nên rất phổ biến. Hơn nữa, trong mô hình Decision Tree thì rất nhạy cảm với nhiễu (outlier) nên ta thường phải tìm cách loại bỏ những điểm này, nhưng với Random Forest thì việc tạo ra nhiều tập dữ liệu con ngẫu nhiên nên không bị ảnh hưởng bởi nhiễu.
-
Tuy nhiên một trong những điểm yếu của các phương Ensemble Learning nói riêng và Random Forest nói chung là tính toán mất khá nhiều thời gian so với thông thường, đặc biệt là bước predict thì điểm dữ liệu mới này phải đi qua tất cả các model rồi mới có thể voting/averaging. Tất nhiên là ta có thể sử dụng nhiều máy để train các mô hình khác nhau.
-
Ngoài ra có một điểm yếu lớn đó là việc hiểu thực sự bên trong mô hình Random Forest làm gì không dễ dàng. Đã có rất nhiều lí thuyết được đưa ra để nhằm chứng minh sự hiệu quả của mô hình nhưng khá định tính. So với mô hình Decision Tree thì Random Forest có thể cải thiện kết quả cuối cùng tuy nhiên Decision Tree có thể giúp trả lời được khá nhiều câu hỏi liên quan tới mô hình làm gì và tại sao.
-
Ngoài Random Forest còn có các mô hình thuộc họ Ensemble Learning rất mạnh đó là Boosting, Stacking… về vấn đề này mình sẽ giới thiệu ở một bài khác.
6. Tham khảo
[1] Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
[2] Understanding Random Forests Classifiers in Python by Avinash Navlani
[3] Decision Tree vs. Random Forest – Which Algorithm Should you Use? by Abhishek Sharma